
题目
现在有一个puzzle.mp3音频,请尝试从中破解出有效信息。
下载音频地址:puzzle download
题目不难但是需要一些技巧解决。
如果您想先自己尝试,请不要翻开下方题解。
如果您想先自己尝试,请不要翻开下方题解。
如果您想先自己尝试,请不要翻开下方题解。

题解
下载音频后我们使用ffprobe分析音频采样率,声道数量,和量化位深。
1
2
3
4
5
6
7
8
fcc@MacBook-Pro pywave % ffprobe puzzle.mp3
ffprobe version 8.0.1-tessus https://evermeet.cx/ffmpeg/ Copyright (c) 2007-2025 the FFmpeg developers
built with Apple clang version 17.0.0 (clang-1700.4.4.1)...
Input #0, mp3, from 'puzzle.mp3':
Metadata:
encoder : Lavf62.3.100
Duration: 00:00:17.22, start: 0.025057, bitrate: 192 kb/s
Stream #0:0: Audio: mp3 (mp3float), 44100 Hz, mono, fltp, 192 kb/s, start 0.025057
我们得到一些基本信息,音频是mp3格式,采样率44100Hz,单声道,32-bit浮点。打开听就是普通的摩斯电码滴答声,速度很快,边听边记有些困难,我们尝试使用python程序处理。
由于这里时域数据比频域数据更加重要,我们用ffmpeg把音频转换成wav波形格式进行处理。
1
ffmpeg -i puzzle.mp3 z2.wav
1
2
3
4
5
6
7
8
fcc@MacBook-Pro pywave % ffprobe z2.wav
ffprobe version 8.0.1-tessus https://evermeet.cx/ffmpeg/ Copyright (c) 2007-2025 the FFmpeg developers
built with Apple clang version 17.0.0 (clang-1700.4.4.1)...
Input #0, wav, from 'z2.wav':
Metadata:
encoder : Lavf62.3.100
Duration: 00:00:17.22, bitrate: 705 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 44100 Hz, 1 channels, s16, 705 kb/s
现在我们得到了采样率44100Hz,单声道,16-bit的音频。
我们用matplotlib把波形画出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import wave
import numpy as np
from matplotlib import pyplot as plt
def read_wav_8bit(filepath):
with wave.open(filepath, 'rb') as wf:
n_channels = wf.getnchannels() # 声道数
sample_width = wf.getsampwidth() # 每个样本的字节数
framerate = wf.getframerate() # 采样率
n_frames = wf.getnframes() # 总帧数
raw_data = wf.readframes(n_frames) # 原始字节数据
# 将字节数据转换为 numpy 数组
if sample_width == 1:
# 8-bit: 无符号整数 [0, 255]
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
elif sample_width == 2:
# 16-bit: 无符号整数 [0, 65535]
audio_data = np.frombuffer(raw_data, dtype=np.uint16)
else:
raise ValueError(f"不支持的样本宽度: {sample_width}")
return framerate, n_channels, sample_width, audio_data
framerate, n_channels, sample_width, audio_data = read_wav_8bit("z2.wav")
print(len(audio_data))
look = int(len(audio_data))
plt.plot(np.arange(0, look) / framerate, audio_data[:look])
plt.plot([0, look / framerate], [65535, 65535], color='r')
plt.show()
我们同时在65535的高度画了一条红线,得到下图
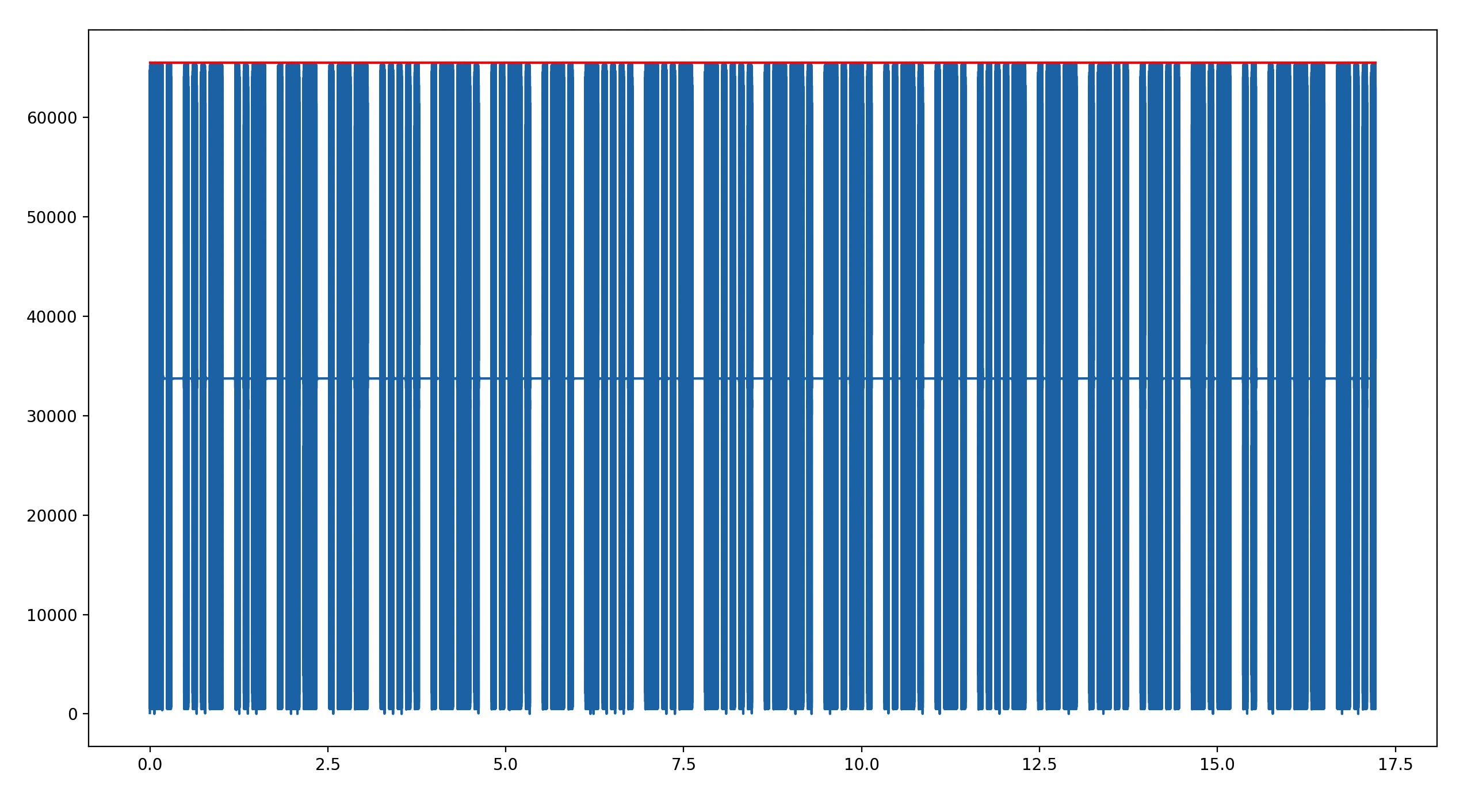
那接下来就需要了解一些摩斯电码基础知识,摩斯电码由点(.)和杠(-)组成,点是摩斯电码时间标记的基本单位,记为一单位,以下是不同元素占用时长的单位数
- 点 1单位
- 杠 3单位
- 点杠间隔 1单位
- 字母间隔 3单位
- 词间隔 7单位
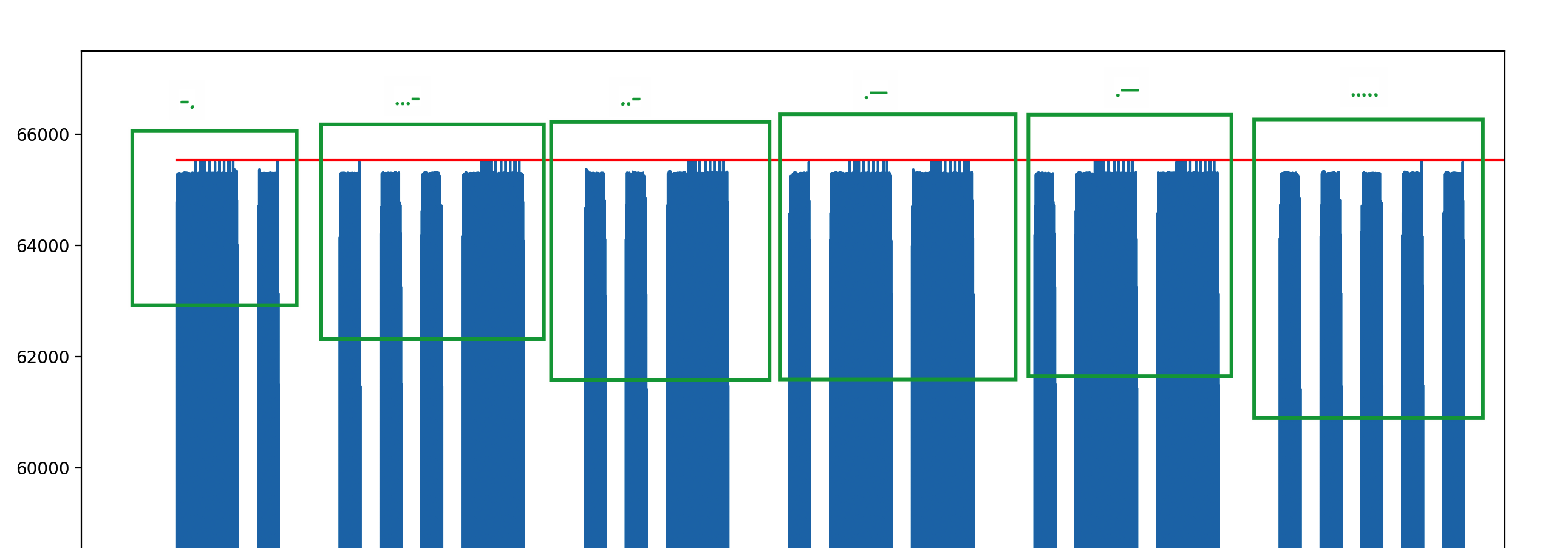
显然,图中并没有7单位的间隔,说明根本没有词。我们可以把波形按照字母间隔,也就是3单位空白拆分,得到每个字母对应的摩斯电码,如下图。
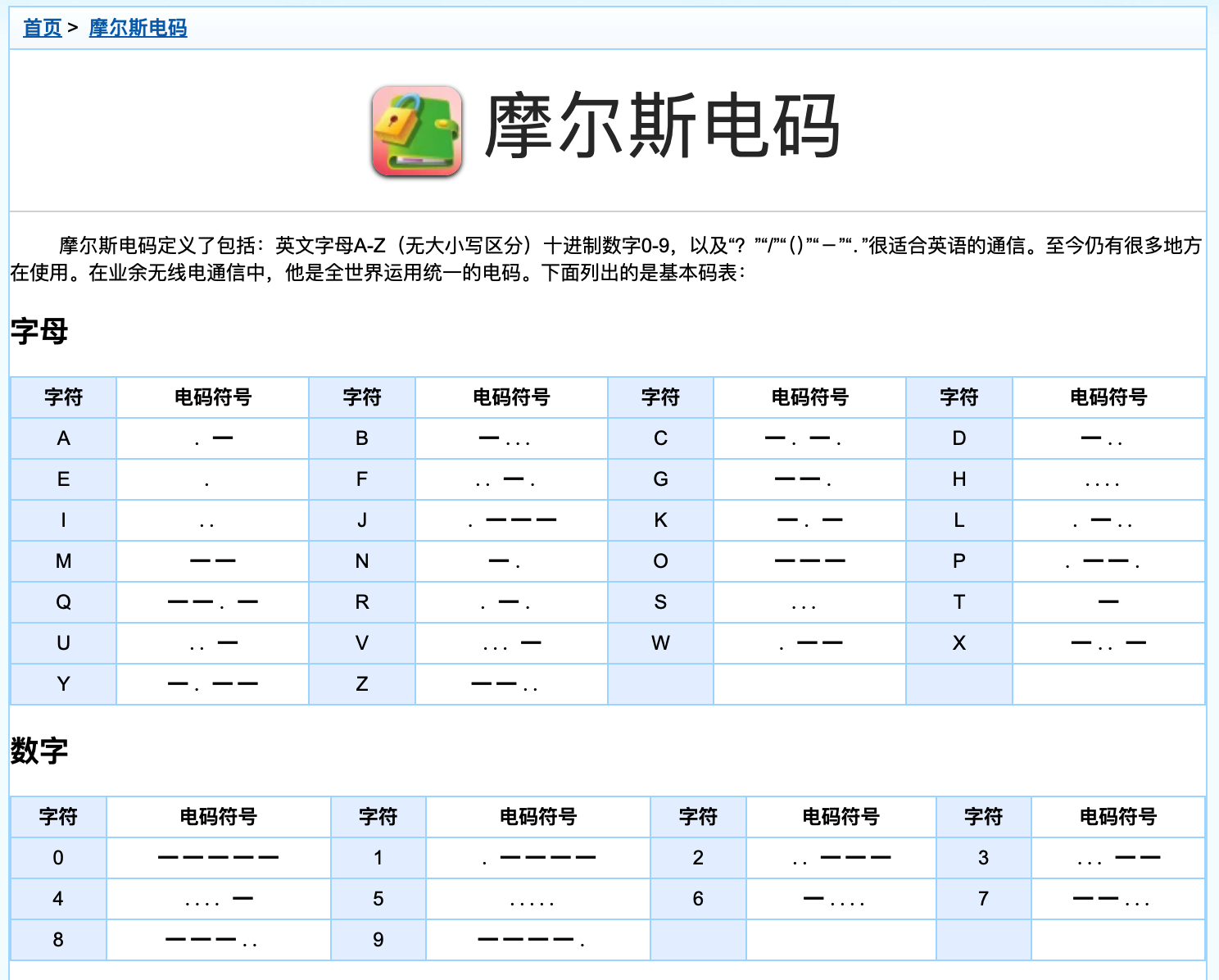
附上一张摩斯电码表。
这段音频有24个字母,一个个读写还是有点累,如果做的更多一些,我们可以用numpy再次对音频分析。
注意到这个音频的1单位对应的时长是60ms,也就是20wpm。
我们每次读取音频60ms的数据点,计算方差,然后将这组方差数据做归一化,方差大的组认定为有声音,方差小的组认定为无声音,我们这里使用0.9当做分界。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import wave
import numpy as np
# MorseTool是笔者自己写的
from MorseTool import Morse
framerate, n_channels, sample_width, audio_data = read_wav_8bit("z2.wav")
ALEN = len(audio_data)
FRAME_RATE = 44100 # 44.1kHz
DURATION = 0.06 # 60ms
# 解码成0101
SEGMENT_LEN = int(DURATION * FRAME_RATE)
SEGMENT_COUNT = int(ALEN / SEGMENT_LEN)
vars = np.zeros(SEGMENT_COUNT)
for i in range(SEGMENT_COUNT):
segmentData = audio_data[i*SEGMENT_LEN:i*SEGMENT_LEN+SEGMENT_LEN]
vars[i] = np.var(segmentData)
vars = vars / np.max(vars)
condition = vars > .9
vars[condition] = 1
vars[~condition] = 0
zocode = vars.astype(int).tolist()
zocode = map(str, zocode)
zostr = "".join(zocode)
# zostr: 11101000101010111000101011100010111011100010...
def parse_all(zos: str):
words = zos.split("0"*7)
result = " ".join([parse_word(w) for w in words])
return result
def parse_word(zow: str):
word = zow.split("0"*3)
result = "".join([parse_char(c) for c in word])
return result
def parse_char(zoc: str):
bits = zoc.split("0")
result = ""
for b in bits:
if len(b) == 1:
result += "."
elif len(b) == 3:
result += "-"
else:
pass # never
char = [k for k, v in Morse.codes.items() if v == result]
if len(char) == 0:
return ""
return char[0]
secret = parse_all(zostr)
print(secret)
像这样,按照7空位分词,3空位分字母,1空位分点杠,我们将摩斯电码音频解析完成。
1
NVUWW5PFR6X6PCFR4WLLKIJB
这看上去仍然不是人话,说明还要二次加工,经验告诉我们这可能是base64或者base32编码,但是鉴于这段摩斯电码只有A-Z0-9这36个字符,base32的可能性更大。
接下来编写python脚本,将这串字符用base32转成字节,再用utf-8编码decode。这里utf-8也是猜的,因为这是最常用的编码,在别的谜题中也许得多试几个。
1
2
3
4
5
6
import base64
encoded_str = "NVUWW5PFR6X6PCFR4WLLKIJB"
decoded_bytes = base64.b32decode(encoded_str)
decoded_str = decoded_bytes.decode("utf-8")
print("解码:", decoded_str)
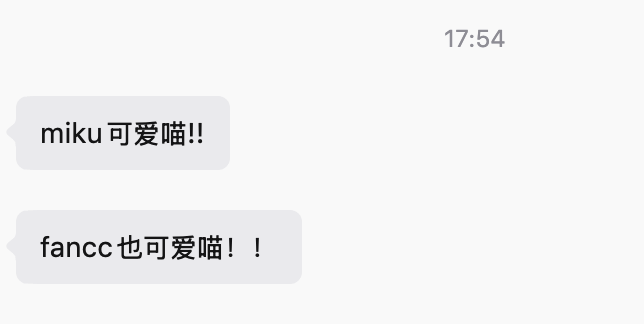
我们得到答案
1
miku可爱喵!!
感谢我的好朋友,愿意破解我亲手设计的谜题!真的很开心!谢谢你!
附录
谜题生成用到的部分脚本。
main.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from WaveTool import WaveUtil
from MorseTool import Morse
from pprint import pp
import numpy as np
FRAME_RATE = 44100
SAMPLE_WIDTH = 1 # Bytes
FREQ = 600
DURATION = 0.06 # 60ms
TEXT = "NVUWW5PFR6X6PCFR4WLLKIJB"
myWave = WaveUtil("puzzle.wav", FRAME_RATE, SAMPLE_WIDTH)
def get_dots(duration):
return duration * FRAME_RATE
txt = Morse.get_codes(TEXT)
data = Morse.parse_to_data(txt)
voiceData = np.array([])
for item in data:
dots = get_dots(DURATION * item["duration"])
xpoints = np.arange(0, dots)
if item["type"] == 0:
ypoints = np.zeros_like(xpoints)
else:
ypoints_float = np.pow(np.sin(2 * np.pi * FREQ * xpoints / FRAME_RATE), 1)
ypoints = (ypoints_float + 1) / 2 * (SAMPLE_WIDTH << 8)
voiceData = np.concatenate((voiceData, ypoints))
print(txt)
# print(data)
print("FULL LENGTH", sum([i["duration"] for i in data]))
myWave.write_wav_8bit(voiceData)
WaveTool.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import wave
import numpy as np
from pathlib import Path
class WaveUtil:
def __init__(self, file, framerate, sample) -> None:
self.file = str(Path(__file__).parent / file)
self.framerate = framerate
self.sample = sample
def write_wav_8bit(self, data):
raw = data.astype(np.uint8).tobytes()
with wave.open(self.file, 'wb') as wf:
wf.setnchannels(1)
wf.setsampwidth(self.sample)
wf.setframerate(self.framerate)
wf.writeframes(raw)
print("Successfully wrote", self.file)
MorseTool.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
import re
class Morse:
codes = {
"A": ".-",
"B": "-...",
"C": "-.-.",
"D": "-..",
"E": ".",
"F": "..-.",
"G": "--.",
"H": "....",
"I": "..",
"J": ".---",
"K": "-.-",
"L": ".-..",
"M": "--",
"N": "-.",
"O": "---",
"P": ".--.",
"Q": "--.-",
"R": ".-.",
"S": "...",
"T": "-",
"U": "..-",
"V": "...-",
"W": ".--",
"X": "-..-",
"Y": "-.--",
"Z": "--..",
"0": "-----",
"1": ".----",
"2": "..---",
"3": "...--",
"4": "....-",
"5": ".....",
"6": "-....",
"7": "--...",
"8": "---..",
"9": "----."
}
def __init__(self) -> None:
pass
@classmethod
def get_code(cls, s: str):
return cls.codes.get(s, "")
@classmethod
def get_codes(cls, s: str):
s = re.sub(r"\s+", " ", s)
morseList = [cls.get_code(c.upper()) if c != " " else "|" for c in s]
result = "/".join(morseList)
result = re.sub(r"/\|/", "|", result)
result = re.sub(r"^\|/", "|", result)
result = re.sub(r"/\|^", "|", result)
return result
@staticmethod
def parse_to_data(codes):
data = []
last = "x"
for c in codes:
# 处理小间隔
if (c in ".-") and (last in ".-"):
data.append({
"type": 0,
"duration": 1
})
# 正常处理
if c == ".":
data.append({
"type": 1,
"duration": 1
})
elif c == "-":
data.append({
"type": 1,
"duration": 3
})
# 字间隔 词间隔
elif c == "/":
data.append({
"type": 0,
"duration": 3
})
elif c == "|":
data.append({
"type": 0,
"duration": 7
})
else:
raise Exception("解析错误")
last = c
return data